Wrapping one’s head around Repetition and Definition Levels in Dremel, powering BigQuery
Like every GCP’s BigQuery user, I was amazed at the speed that GCP’s BigQuery offers to its users (Processing almost TB/s in certain cases) and I wanted to deep dive into the underlying data structures that power BigQuery’s speed. My initial resort was reading the famous Google’s research paper on Dremel hosted at https://ai.google/research/pubs/pub36632 titled “Dremel: Interactive Analysis of Web-Scale Datasets”
Of course, that was an outstanding achievement of Google engineers and that paper explained the complexities involved in designing the underlying datasets and processing them to provide speeds that were once conceived unfathomable. However, like most of the people I had difficulties wrapping my head around the concept of repetition and definition levels in Dremel and this blog post is targeted at people who would like to understand them and compute them for a given set of records.
I shall elucidate the Column striped representation of the example quoted in the Dremel paper.[I am maintaining the same figure# to make it easy referring back to the research paper]


So, what we are trying to accomplish here is how the sample records r1 and r2 listed in Figure2 are transformed into the Column-striped representation in Figure3.
Let's establish one understanding since we reached till here. You have data in a particular format. You have an associated structure for that data. You are transforming that data into a different format that is efficient for reducing storage footprint and retrieval time. But, you need a method to reconstruct the records from the stored format without losing the structure of the data. That’s where two pivotal terms repetition and definition levels arise. They help to reconstruct the record from the columnar storage.
Repetition Level: Consider field Code in Figure 2. It occurs three times in r1. Occurrences ‘en-us’ and ‘en’ are inside the first Name, while ’en-gb’ is in the third Name. To disambiguate these occurrences, we attach a repetition level to each value. It tells us at what repeated field in the field’s path the value has repeated.
Definition Level: Each value of a field with path p, esp. every NULL, has a definition level specifying how many fields in p that could be undefined (because they are optional or repeated) are actually present in the record. To illustrate, observe that r1 has no Backward links. However, field Links is defined (at level 1). To preserve this information, we add a NULL value with definition level 1 to the Links.Backward column. Similarly, the missing occurrence of Name.Language.Country in r2 carries a definition level 1, while its missing occurrences in r1 have definition levels 2 (inside Name.Language) and 1 (inside Name), respectively +
These extracts from the paper make complete sense, but that does not make the computation of repetition and definition levels clear. So, let's look at how do we compute the repetition and definition levels in practice with a few examples.

A (repetition level, definition level) pair represents the delta between two consecutive paths pX−1 and pX. Repetition level encodes the length of the common prefix of pX−1 and pX, while definition level encodes the length of pX (or, alternatively, the length of pX’s suffix). For example, the common prefix of the first two paths in Figure4 is r1.Name1 and has length 2. Path lengths are encoded compactly as follows. The common prefix of two consecutive paths always ends on a repeated field, so we define the repetition level as the number of repeated fields in the common prefix (including the first path element identifying the record).
The definition level specifies the number of optional and repeated fields in the path (excluding the first path element). We do not count “required fields” since they are always present. A definition level smaller than the maximal number of repeated and optional fields in a path denotes a NULL
(Extract from https://storage.googleapis.com/pub-tools-public-publication-data/pdf/37217.pdf)
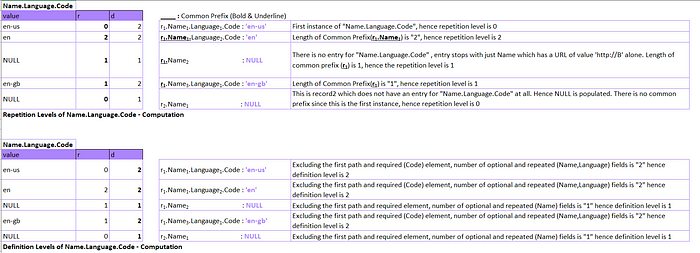
So, how exactly are they computed? Let's begin with the field “Name.Language.Code”

First things first — Let's compute how many rows we expect for the field — “Name.Language.Code”
i) We have two records and due to the lossless nature of the encoding, we have to attribute NULLs too when we do not have an entry for a field
ii) As highlighted in Figure5, we have 3 instances of the field of interest in record1 and 1 NULL (Name.Url : ‘http://B’. This level did not have Language detail, so we populate a NULL for this field, but repetition and definition level carry importance to identify the exact position the NULL). The same logic applies for record2 where we shall populate NULL for record2, but repetition and definition level shall vary from the NULL that we apply in record1
iii) So, we anticipate 4+1 = 5 records for this field
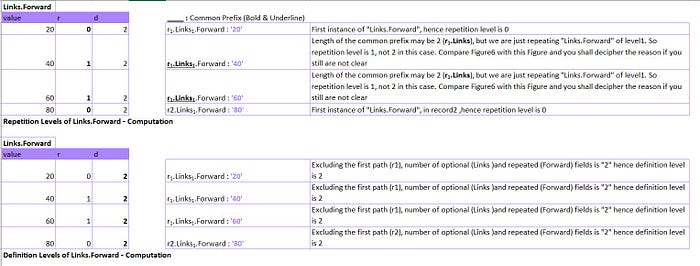
Let’s look at yet another example and compute repetition and definition levels, this time — for “Links.Forward”
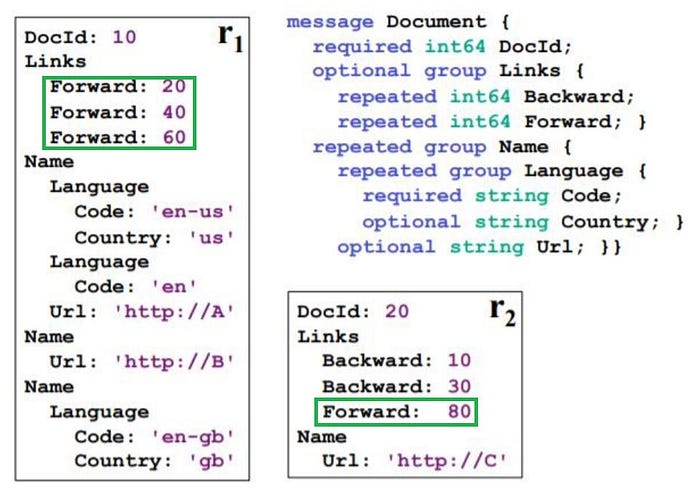
Again, First things first — Let’s compute how many rows we expect for the field — “Links.Forward”
i) We have two records and both the records have the field Links.Forward with different repetition
ii) As highlighted in Figure7, we have 3 instances of the field of interest in the same level in record1 and 1 instance of it in record2. There are no NULLs for the field in the recordset
iii) So, we anticipate 3+1=4 records for this field.
By this time, I hope a logical understanding of repetition and definition levels and how to compute them is in place. Lets look at one final example and wrap up this article and hope you guys would have wrapped up your head too around this seemingly straight forward but tricky concept :)
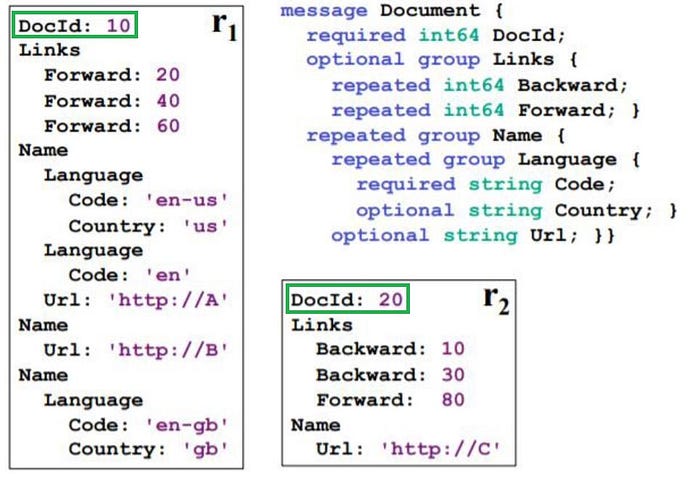
It is straight forward that DocId, in this case, is a unique id for each document, in this case since we have two records (documents), we expect 2 records

Similarly, if we compute the definition levels for Links.Backward, Name.Language.Country and Name.Url, we can cross check the results with values listed in Figure3.
It is worth noting that the open-source Apache Parquet project has taken the findings from Dremel and have implemented it. So next time when you encounter repetition and definition levels anywhere in this context, I hope this article helps you.
